
服务咨询热线:
0752-5880-900(8280)服务咨询热线:
0752-5880-900(8280)弱智吧我们可以简单交流一下★★◆■★,这个工作是我们这边的intern和和一些科研机构合作的。当时是我们的想法,这些数据可以对模型训练有一些帮助,我们做数据团队一直有这种奇思妙想去开拓不同的数据场景★■■★★,提高数据的质量和数据的diversity。
LMSYS Org发布的Chatbot Arena◆★■★◆,关键词是盲测和开放。用通俗的语言来描述就是,它的模式是通过众包的方式对大模型进行匿名评测,用户可以在官网输入问题,然后由一个或者多个用户并不知道品牌的大模型同时返回结果,用户根据自己的期望对效果进行投票。
黄文灏:首先我们没有碰到数据荒的问题■◆,至少我们看到数据还有一两个数量级的增长◆★■◆■,数据还是有很多可以挖掘的一些潜力,这里有我们很多正在进行的工作,具体不太方便透露怎么做,但是我们的确看到数据有很大潜力★■★。而且我们最近在多模态上有一些finding,可以更进一步增加一到两个数量级的数据量。
另一方面是我们很重视infra的建设,就是算法 Infra 其实是一个 co-design 的过程★■★,在这种情况下我们才能够把我们的算力发挥到比较好的水平。
能不能达到第一,能不能超过,当然是一个艰难的任务,但是我们是朝着这个目标在努力,我觉得今天的结果对比一周前,对比去年11月,对比我们成立的时候,都是一个不可思议的飞跃,所以看事情要看这个事情是在上涨还是下跌■★◆■,而不是说你今天还是落后★■★◆★■,因此以后就会落后。
Q:开复之前提过大模型行业发展不能走ofo烧钱烧钱打法,但事实是现在国内确实打起大模型价格战,在这个过程中零一万物和其他初创公司如何在竞争中跑赢大厂■◆?
另外是优化模型的performance表现,它不只是一个纯粹科技和算法的问题■■★,里面还有数据的配比,还有怎么去优化,同时优化训练和influence,还有我们的模型怎么加入多模态等等各种方面的技术◆★★,我觉得我们其实在这方面是不输于美国。
Q:对比海外第一梯队,中国从落后到做小差距■◆,为什么作为后来者的千亿参数模型在scaling law上看起来能够加速的★■■?决定Yi-Large性能提升加速的核心因素也有哪一些?在算力还是不够多的前提下让Yi-X-Large达到GPT4的水平,下一步要解决的最重要的技术问题是什么◆◆■◆■?
李开复:其实跟我们交流过的媒体朋友和外界朋友会知道,我们在去年一直都认为全模态模型◆■★◆◆,omni,也就是我们挑了同样的词已经在做这个工作,这个工作不是人家出来你再跟风能够跟得上的,我们有一定的累积,我们也相信全模态是正确方向。从我们的release schedule 来说,我们只能说在今年你们可以期待一个惊喜,细节请文灏再补充★★★◆■◆。
Q:零一万物的GPU可能是谷歌、微软的5%,但算力对模型发展的限制是客观存在的。当榜上排名靠前的 OpenAI◆◆◆、Google的能力已经靠前,资源还靠前的时候,零一万物怎么应对?
所以我觉得因为我们前面做对了很多事情,follow这个路径下去我们和世界一流梯队之间的差距是会越来越小的。而且我们在这个过程中建立了一个非常强的人才团队,我们有自己培养的★■,也有被我们的使命和愿景吸引过来的人■★◆,我们一块去做这个事情。所有的人都是工程、Infra、算法三位一体,这些人才在将来也会发挥越来越大的作用。
好■★■★,这些话说完了◆★◆■★★,我知道你们的意思是说国内常看到ofo式的疯狂降价,双输的打法。我觉得大模型公司不会这么不理智,因为技术还是最重要的■★◆■,如果是技术不行,就纯粹靠贴钱赔钱去做生意,我们绝对不会跟这样的一个定价来做对标,我们对自己的模型表现是非常自豪的■◆。

李开复★■■■:谢谢■■★,我觉得首先我们也不能确定自己是中国第一★■◆■■,因为中国只有三个模型参加,我们也希望以后可以更确定的验证这一点★■■■■■。
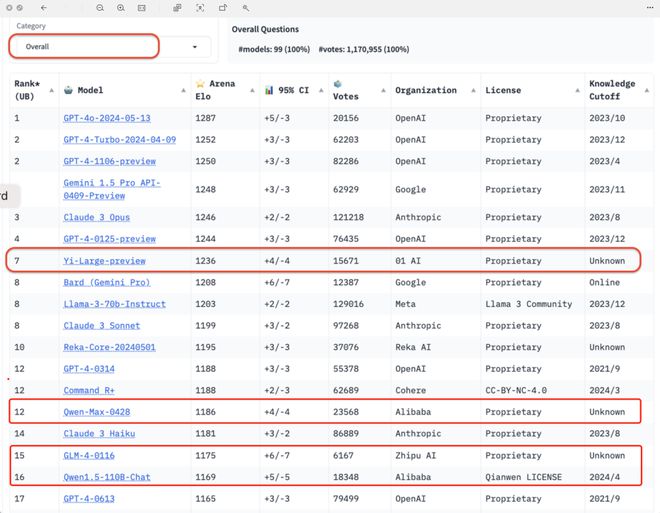
这个让李开复无比兴奋的消息就是◆◆,零一万物提交的“Yi-Large” 千亿参数闭源大模型在LMSYS Org发布的Chatbot Arena取得了总榜排名第七的成绩。
我们也认为我们今天可以看到的模型表现我们超过其他模型★■★◆■,也欢迎不认同的友商来LMSYS打擂台,证明我是错的■■■★。但是直到那一天发生,我们会继续说我们是最好的模型◆◆★。
黄文灏:很多benchmark,包括我们之前大家会比MMLU、GSM8K这些,之前benchmark的题都是死的◆◆,它是有一个确定的评测集,当题目已经完全确定以后★◆◆■◆,大家可以在上面针对题目做一些合成数据,使模型在某一些方面能力变得更高。
而LMSYS它有几方面比较好■■◆■,一方面是它的题是真实用户聊天当中给的题,所以这个题是动态变化的■◆,没有人可以预测题目分布是什么样子的,就没有办法针对题目分布去对模型做单一方面的优化,所以它是overall的模型能力的反映。
我们相信就像一周前我讲的TC-PMF★■,永远是一个跷跷板,你要平衡你需要多强的技术,那你付不付得起这个技术所需要的成本◆★◆★★。业界有各种不同的应用■◆,从最简单的客服应用★◆★■■,到游戏◆■◆,一直到非常难的推理策略、科学发现等等难度◆★■◆◆★,我相信大尺寸的 scaling law,最强大地往 AGI 走的模型,在最难的问题上◆■◆■◆★,大家又愿意花钱的领域里◆★,绝对是有落地场景,而且是最有可能达到AGI★■。
这个我觉得更精确的应该从历史数据来看,看在过去的一两年他们提升了多少★★,我们提升了多少,我们是不是追得非常非常近了,这是一个客观事实。
第三,它是由用户来进行打分的结果,使用GPT-4打分,会有些模型的偏好性★★■◆。用户的打分和用户是更接近的,所以这个榜单也会跟实际应用当中用户的preference更接近,这跟我们做成模因一体的理念是符合的。
李开复:今天我们可以看到的降价我们关注到这个现象■◆■◆◆,我们的定价还是非常合理★■★★◆★,而且我们也在花很大精力希望能够让它再降下来,我觉得一定程度整个行业每年降低10倍推理成本是可以期待的◆★◆,而且必然也应该发生的。今天可能处在一个比较低的点,但是我觉得如果说以后大约以一年降价10倍来看,这是一个好消息,对整个行业都是好消息,因为今天的API模型调用还是一个非常非常低的比例,如果一年降低10倍那众多的人可以用上◆★■■■■,这是一个非常利好的消息。
对要求最高的,需求最高的,需要最好模型的,他们当然用我们尊龙d8898。100万个token花十几块还是花几块钱有很大差别吗★◆★■■■?100万的token对很大的应用★■,很难的应用,我觉得我们是必然之选,我们发布之后得到国内外非常高的评价,而且我们是一个可以横跨中国和外国的API,我们对中国和外国都开放★■,我们有信心在全球范畴是一个表现很好性价比也很合理的一个模型。
我们也有自己在走一个企业级的模型方向,但是现在初步用户在国外,我们认为国外用户的付费意愿或者付费金额比国内大很多,所以虽然我们在中国也非常期望服务国内用户但是按照现在TO B卷的情况,几十万做POC,几百万做一单,我们做一单赔一单的生意,我们早期在AI1.0时代太多了,投多了,我们坚决不做◆◆■。
黄文灏:对■★◆★★◆。我们一直有在做多模态,原生多模态模型◆■◆★,也有一些进展,但是它里面会有一些就是dependency,就是说我们需要一个很强的 language model ◆■◆◆★◆,或者一个 language model 训练的方法。然后接下来我们可能会 scale up多模态模型■■◆◆★■。我们其实在小的size上有一个基本上和GPT-4o功能一样的,就是端到端的多模态模型■■◆◆◆■,然后剩下的可能是scale up 的一些工作
而且我们另外还有几个其他产品在国内国外在测试中,当然万知我们也会继续努力把它越做越好★★■◆★◆,尤其我们对PPT的功能得到非常正面的反馈◆■,因为这是一个跟国内其他大模型很大的差异点,这个是我们面对消费者consumer产品的分享。
同时我们也坦诚■★■,有各种比较小的简单应用的机会。我们的打法是一个都不放过,我们在每一个潜在存在尺寸上发布我们能做到性能最高,而且推理成本最低,这个推理成本也会带来更好的经济价钱跟定价给开发者使用★★■。
Q★■◆■★:目前AI的训练是否遇到数据荒的情况?之前用国内的弱智吧数据训练开源版本的Yi-34B效果显著,零一万物是否会另辟蹊径的训练数据源■◆★◆?目前比较好的数据来源是什么啊?这个我们可以回答的尺度就可以★■★■★★。
刚刚在上周开过发布会的零一万物创始人李开复,时隔一周再一次在线上亲自和小部分媒体沟通,并在沟通会的开始就表示“难掩兴奋★★◆,希望马上开发布会和大家分享这个消息★★◆。”
另外一个角度看★■★◆■,今天我们发布的这个模型在5月的时候可以打败去年11月之前的任何模型,所以我觉得也可以科学的推理出我们落后6个月◆★◆■。
李开复■★■◆◆:现在没有调整的消息来分享,我们现在收到的反馈还是非常正面的,而且有几个开发者一看到,马上就替换别的模型。我认为模型要看它的表现,可能有些领域◆★◆,比如说一些很难收回钱的领域要看价格,反正有足够多的在选我们◆■★◆◆★,我们刚上线,有这么多忠诚的爱好者加入了◆◆■◆■■,我们先服务好他们,价钱再说吧。
■★◆“中国大模型与OpenAI旗舰模型的差距已经从7-10年缩短到了6个月。”李开复在线上沟通会上兴奋地表达。同时,他还呼吁 “无论是出于自身模型能力迭代的考虑,还是立足于长期口碑的视角,大模型厂商应当积极参与到像Chatbot Arena这样的权威评测平台中,通过实际的用户反馈和专业的评测机制来证明其产品的竞争力。这不仅有助于提升厂商自身的品牌形象和市场地位★◆★★,也有助于推动整个行业的健康发展◆★,促进技术创新和产品优化。”
李开复:有■◆★◆★★,我们上周发布的产品基本是我们的方向,我觉得一方面我们已经推出了一些非常成功的海外产品,也是可以算是万知的爸爸,已经在海外得到非常好的成功,今年预期会有大概1个亿的收入■■★,而且不是烧钱模式烧出来的。
所以我觉得后发有后发的优势,但同时我们特别尊敬美国这些创造性,他们的论文希望他们继续写,我们是每一篇都会仔细阅读,我们跟他们有很多学习的地方。但是比执行力,比做出一个很好的体验◆■◆★,做比产品◆◆■■★,比商业模式,我觉得我们强于美国公司。
美国时间2024年5月20日刚刷新的 LMSYS Chatboat Arena 盲测结果★★◆■■,来自至今积累超过 1170万的全球用户真实投票数:此次Chatbot Arena共有44款模型参赛,既包含了顶尖开源模型Llama3-70B,也包含了各家大厂的闭源模型。
首先做的事情是,零一万物每一步在模型训练上的决策都是正确的◆■◆◆★,这个看起来是比较容易的事情,其实做起来是不太容易的。
6个月的差别我觉得不是很大◆■◆■,我觉得是一个不可思议的超级速度的赶追,这些方面我还是非常自豪尊龙d8898◆◆★■■■。
李开复:这是一个动态的问题,我觉得现在来静态的看这个榜单说你还落后那几家,因此它们一定是巨大的算力做出来的。
关于它是不是确定性方向?这是一个开放问题★★■■★◆,大家要通过实验的finding来决定它是不是一个确定性方向■★◆。因为我们的目标要提高智能上限,多模态理解和生成这两个任务是不是都在提高智能的上限。第二个是多模态模型相比文本模型能不能提高智能的上限◆★■。
所以我不认为他们的算力更大就表示我们绝对没有机会,当然他们的算力更大有巨大的优势,但是我觉得客观事实是我们能够把同样的一张GPU挤出更多的价值来★★■,这是今天我们能够达到这些成果的一个重要理由★◆。
同时,李开复也十分直接地抨击了“作秀式的评测方式”,他指出■■“相反,那些选择作秀式的评测方式,忽视真实应用效果的厂商■■,模型能力与市场需求之间的鸿沟会越发明显★◆,最终将难以在激烈的市场竞争中立足。”
就像你如果有一台特斯拉★◆,它不会因为别的牌子的车比它卖的很便宜它就觉得它要降价★★◆,我们就是特斯拉■◆◆★★,我们的价钱是合适值得的。
Q■★◆:Yi-Large确实在中国大模型排名第一,但是确实前面还有国外大厂模型★★★★,您认为造成这个差距的原因主要是什么■★★,是人才吗★■◆?如何追赶◆■?
我刚刚说到Google的一个VP,他觉得我们是不可思议的达到这样一个成果★■■★■,所以我觉得我不会认为算力远远落后◆★■★■。我们算力一直远远落后,我们一年前算力也是只有Google、OpenAI的5%,现在还是,我们如果用5%的算力能够把落后快速拉近■■,未来我们还是期待有惊人的结果。
李开复◆◆■◆:我觉得这两个都是客观公正的★★■◆■■,Alpaca Eval是斯坦福大学用GPT4评测的,今天的LMSYS是真的几万个人评估一个模型◆★★,严格要我挑哪一个更可信的话,虽然我们在Alpaca排名更高◆■★■◆★,但是我觉得LMSYS是更可信的★★◆。
李开复:我补充一点,问题是有关超大模型和有些公司做小模型★■★。我们的计划是从最小到最大的模型都希望能够做到中国最好,所以我们刚才讲了在6B、9B、34B★★,未来可能有更小的模型发布◆■◆■■◆,它们都是同样尺寸达到业界最佳■■,不敢说第一,但是总体来说是第一梯队或者是最好的一两名这样的表现,而且在很多方面◆◆■,在代码方面、中文方面、英文方面表现都是非常好。
第二个问题我先简单说一下■◆,由开复老师主要讲。我觉得做更大的模型是我们会一直追求,因为我们公司使命是追求AGI★◆★,同时让它变得accessible and beneficial to all human beings(有益于人类且普惠)。所以我们觉得我们会继续去做更大的模型,追求模型的能力同时和应用做更好的衔接。当然我们自己是 believe in scaling law(相信规模定律)的,所以我们在模型变得更大,或者我们用更多的计算资源的时候,我们的模型智能会逐步提升◆■★■。
黄文灏:首先我觉得我们一开始落后没有7-10年没有那么多,可能之前落后一段时间■★,但现在很接近了。
包括我们一开始花了很长时间去做数据质量提升■■★,我们去做scaling Law,没有很着急的推出第一款模型■◆◆■★,把我们的基础做的比较好★★■,接下来我们不停地提升数据质量,不停地在做scale up■★■◆,我们在基础能力建设完以后,在scale up的中会非常顺畅。
Q■◆★:GPT-4o开始做原生多模态模型★◆★,统一文本、音频★◆◆、图像、视频的输入输出的多模态大模型会是一个确定方向吗?可否透露一下零一万物在多模态的进展★★◆◆■。
在这个榜单上,我们也看到了中国大模型的身影,智谱GLM4★★◆■◆★、阿里Qwen Max★★、Qwen 1■■■◆■.5、零一万物Yi-Large、Yi-34B-chat 此次都有参与盲测■■■◆,零一万物提交的★◆■◆★“Yi-Large” 千亿参数闭源大模型总榜排名第七,在总榜之外,LMSYS 的语言类别上新增了英语★■◆★■、中文、法文三种语言评测,开始注重全球大模型的多样性。Yi-Large的中文语言分榜上拔得头筹,与 OpenAI 官宣才一周的地表最强 GPT4o 并列第一,Qwen-Max 和 GLM-4 在中文榜上也都表现不凡。
到今天为止,我们刚宣布的性能肯定是国内性价比最高。大家可能有用千token、百万token◆■,大家可以自己测算一下。
这6个月怎么来■★★■?可以回到LMSYS 6个月以前的榜◆★★◆,或者今天比我们排名在前面的几家■★★◆◆■,几乎都是今年发出来的模型,去年的模型还在榜单上,我们已经打败了。
Q■◆■★★★:有业内专家说过所有的基准测试都是错的,您怎么看?现在大模型发布给的测评对比有哪些价值吗?第二个问题比较,零一万物后续会推出更大参数的模型吗■■?现在一些企业开始做小模型,您认为现在卷参数还有意义吗?
在简短的媒体沟通会上★■■★■,李开复和零一万物模型训练负责人黄文灏也坦诚回答了媒体关于模型评测的客观性★★■★◆、模型成本下降、全球大模型竞争差距等问题,以下为部分访谈内容实录◆◆:
过去一年的模型能力大战中,伴随每次新模型的发布,Benchmark评分就会作为标准动作被同时公布。但是,究竟如何解读这些评分◆■■◆?哪些才是有公信力的?行业内并没有统一的标准。
为什么Sam Altman会引用LMSYS 的结果?为什么在这个榜单取得成绩会让李开复兴奋不已?
在收集真实用户投票数据之后,LMSYS Chatbot Arena还使用Elo评分系统来量化模型的表现★◆◆◆,进一步优化评分机制,力求公应参与者的实力。最后用Elo评分系统来得出综合得分——每个参与者都会获得基准评分■★★◆■★。系统会根据参与者评分来计算其赢得比赛的概率◆★,一旦低分选手击败高分选手■◆◆■★★,那么低分选手就会获得较多的分数,反之则较少★■。
Q:现在有很多榜单,比如之前零一万物引用的斯坦福的Alpaca Eval◆◆■■■★,现在又有大模型竞技场,哪些评测会比较客观呢?
黄文灏:先回答第一个问题,之前的benchmark的确有一些题目的动态变化性不够,所以会发生有人说的,比如说定向优化模型某项能力,我觉得不是刷榜,而是把模型某些能力做提升。这些提升在单一能力上有价值,但是比较的时候大家不知道这个模型提升了这方面能力■◆★■,那个模型提升那方面的能力◆■,所以大家在比较的时候不一定会客观公正,而LMSYS是提供一个最好的更接近于用户真实场景的一种评测方式,它的方式也是因为题目动态随机性不适合大家做优化◆◆,所以可以看作一个比较好的标准去衡量模型的能力。
换一个角度来说◆◆★★■,如果只评估千亿模型,至少在这个排行榜上是世界第一,这些点我们还是很自豪★◆★■,在一年前我们落后OpenAI跟Google 开始做大模型研发的时间点有7到10年■◆■■■◆,现在我们跟着他们差距在6个月左右,这个大大的降低。
我简单说一下我们在某些方向上看到一些比较promising的初期实验结果,我们是相信这个可以提高智能上限。
但我也不是特别认为我们跟全球有差距,当然你要用他们最好的对我们最好的是有一定的差距◆■■★◆◆,但是同时可能要考虑到他们比如说Google团队是2000人■■◆,OpenAI是1000人■★■,在我们这里把模型加infrastructure加起来也不到100人,而且我们用GPU算力做这个训练不到他们的1/10,我们的模型尺寸也不到他的1/10◆■★。

但是在同一本书里我也说了■◆■★◆★,中国人的聪明、勤奋★★★■、努力是不容忽视的,我们把这7-10年降低到只有6个月,就验证了做好一个模型绝对不只是看你多能写论文,多能发明新的东西,先做或后做,做的最好的才是最强的◆■★■★★,Google搜索比雅虎晚做很多,但是完全没得比。
如果你说美国人才有没有独特的地方?肯定是有的,从我写的《AI·未来 》这本书之后,我一直都坚持美国是做突破性科研◆■★★■,创造力特别强的一批科学家,在这方面在全世界是没有对手的。










